Đầu tiên chúng ta tham khảo cho biết python nó là gì và làm những gì thì vào đây: /python
Trước mắt chúng ta sẽ chiến đấu thông qua Colab (google) nhé. Và tại sao làm python thì vào đây kéo xuống cuối cùng mình có giải thích rồi
Đầu tiên các bạn cứ vào google drive: https://drive.google.com/drive/u/0/my-drive
Tạo 1 folder tên python nhé
Việc này nhẹ mà lương cao!
Vậy là chúng ta có folder tên python trên driver.
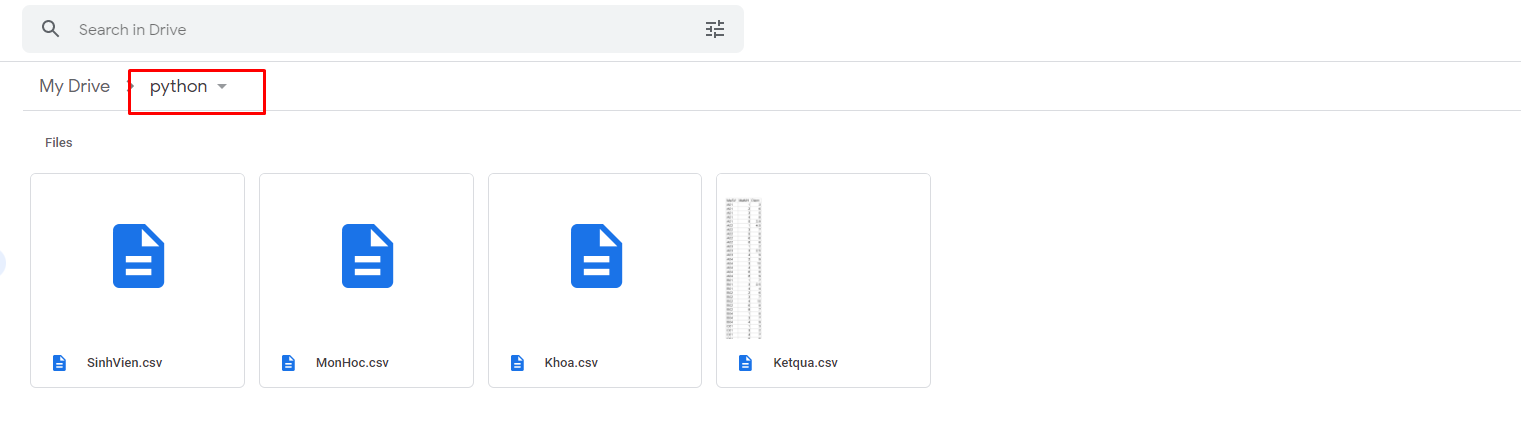
Tải file database mẫu tại đây
Giải nén và upload nó lên Driver như hình phía trên nhé
Sau đó thì sử dụng lại database từ buổi học hôm trước; mình tạm thời xuất cứng nó ra thành file csv cho dễ thao tác trước nhé còn connect databse SQL như thế nào theo python thì search google.
Hoặc làm theo code mẫu này
import pyodbc
import matplotlib.pyplot as plt
conn = pyodbc.connect('Driver={SQL Server};'
'Server=.\MSSQL2019;'
'Database=DEVMaster_Buoi3;'
'Trusted_Connection=yes;')
Sử lại thông số nhé! Nếu các bạn đã cài python trên máy rồi thì mới dùng đến thằng này (không thì bỏ qua)
Giờ bắt đầu nào:
Chuột phải vào folder python add colab vào (nếu chưa có)
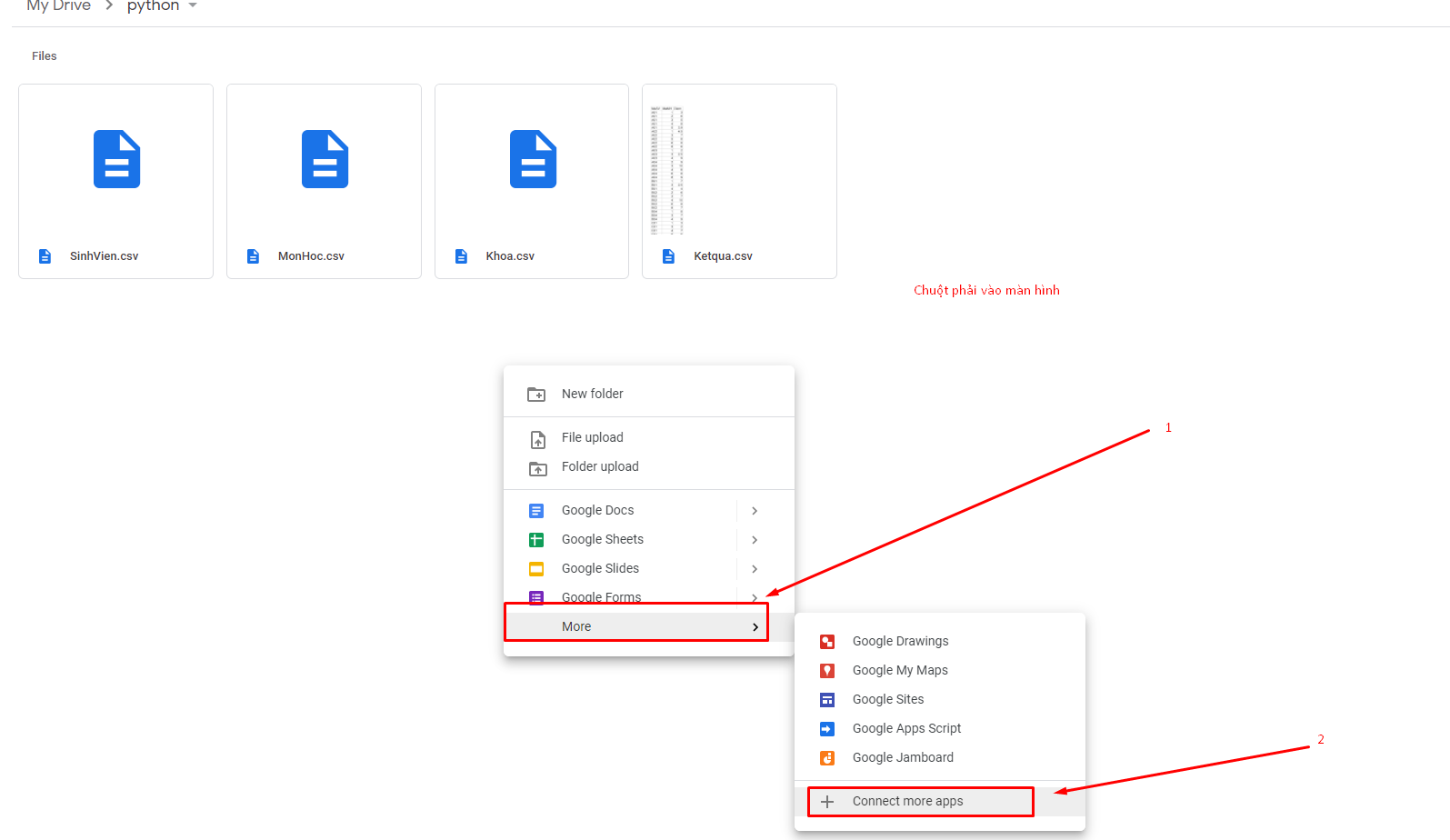 Add thêm Colab vào goolge driver
Add thêm Colab vào goolge driver
Tìm đúng cái có tên là: Colaboratory
 Thêm Colaboratory vào driver
Thêm Colaboratory vào driver
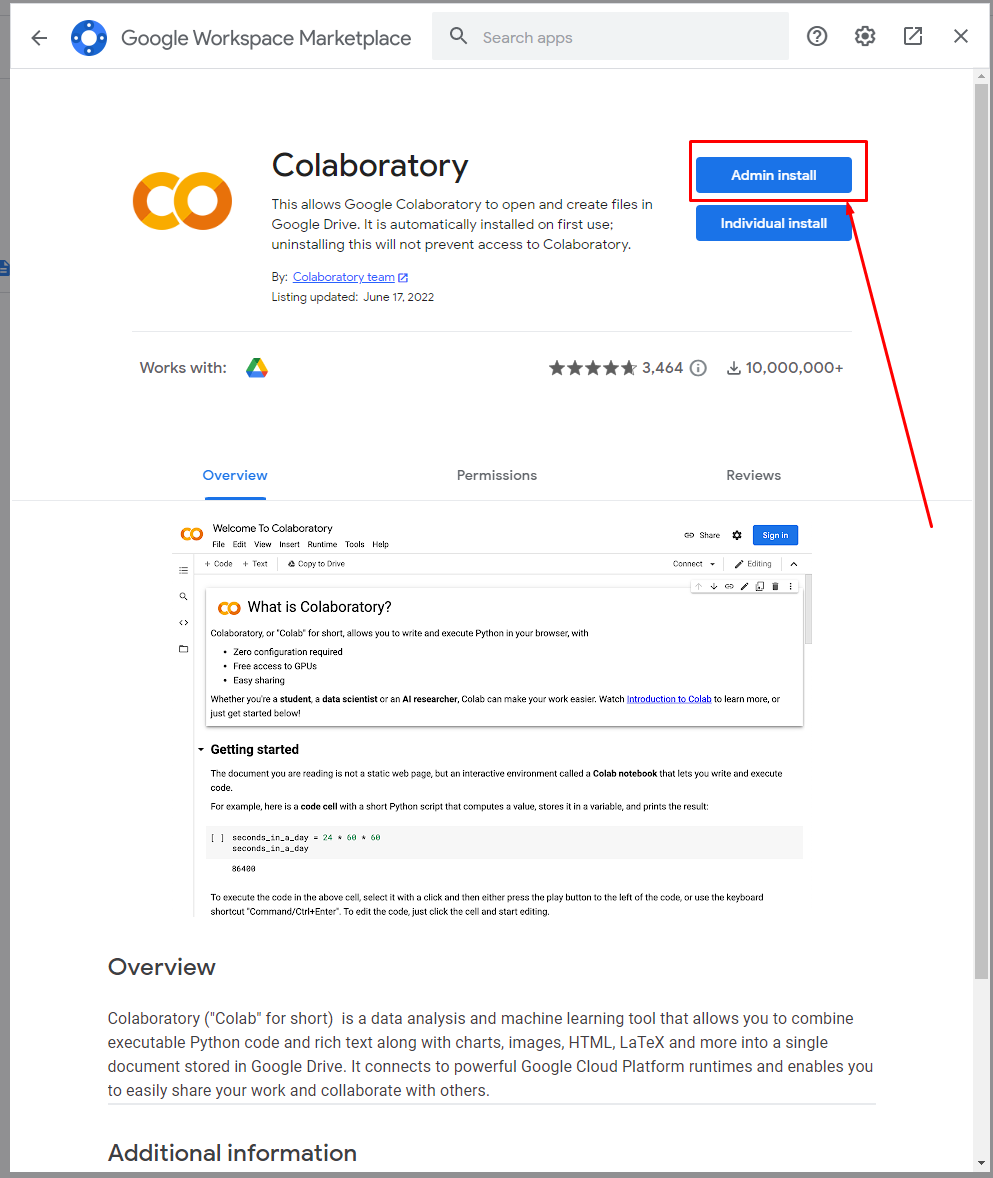
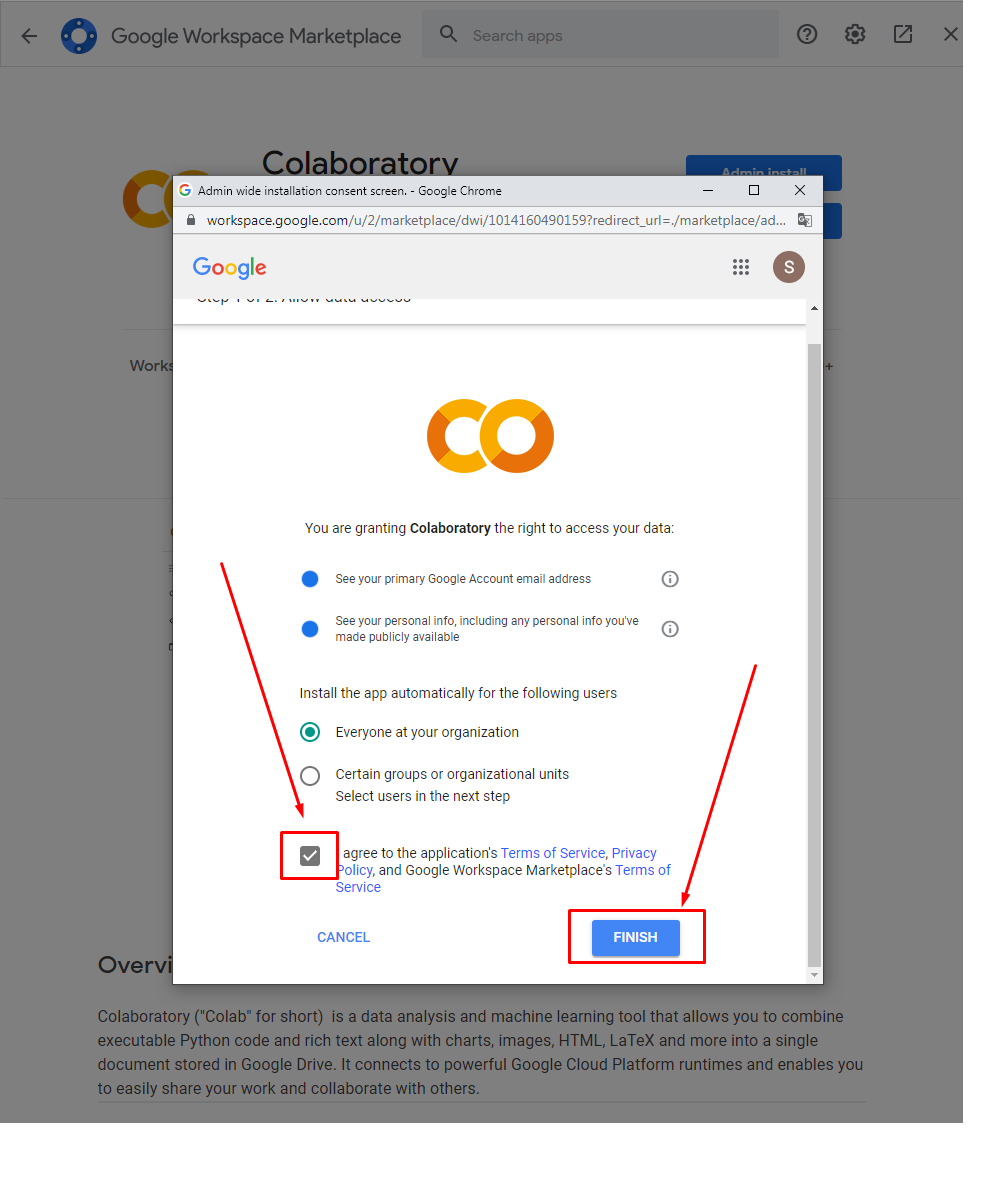 Cứ nếch thôi - Việc nhẹ lương cao
Cứ nếch thôi - Việc nhẹ lương cao
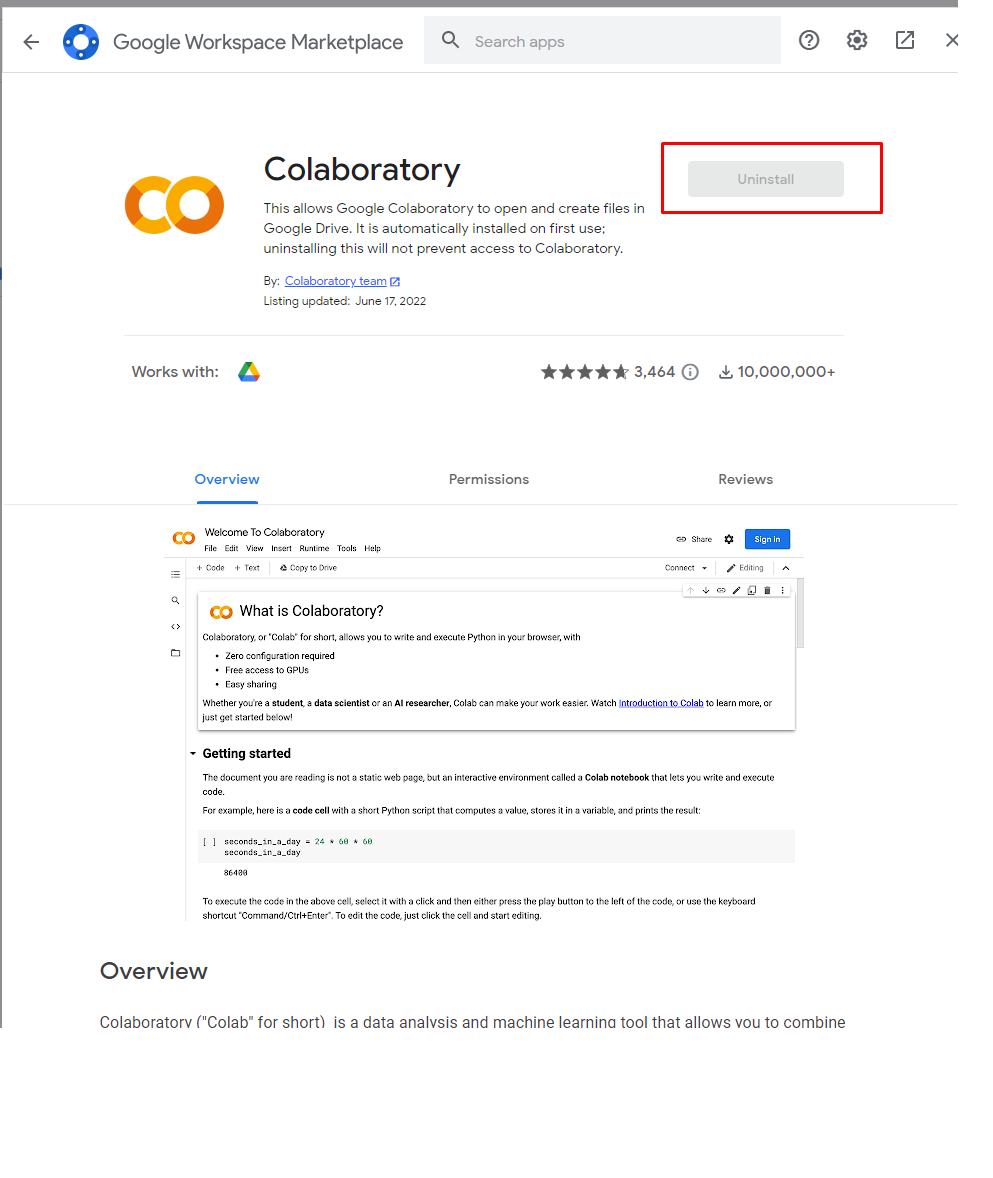 Như này xong rồi!
Như này xong rồi!
Giờ chúng ta sẽ tiến hành mở Colab lên nhé
 Mở colab theo folder python
Mở colab theo folder python
Đây rồi; trông xịn xò con bò cực luôn
 Màn hình chính colab
Màn hình chính colab
OK!
Giờ tiếp tục nào:
Ở đây mình chỉ sử dụng mỗi thư viện pandas của python; pandas nó có gì thì đọc ở đây: https://pandas.pydata.org/docs/user_guide/index.html#user-guide
Chúng ta sẽ tiến hành cái đặt pandas cho colab bằng dòng lệnh
!pip install pandas
(Thằng colab nó install thì phải thêm ! (chấm than) phía trước, hơi khác một chút với bản cài trên máy tính; vì sao lại thế thì mình chịu)
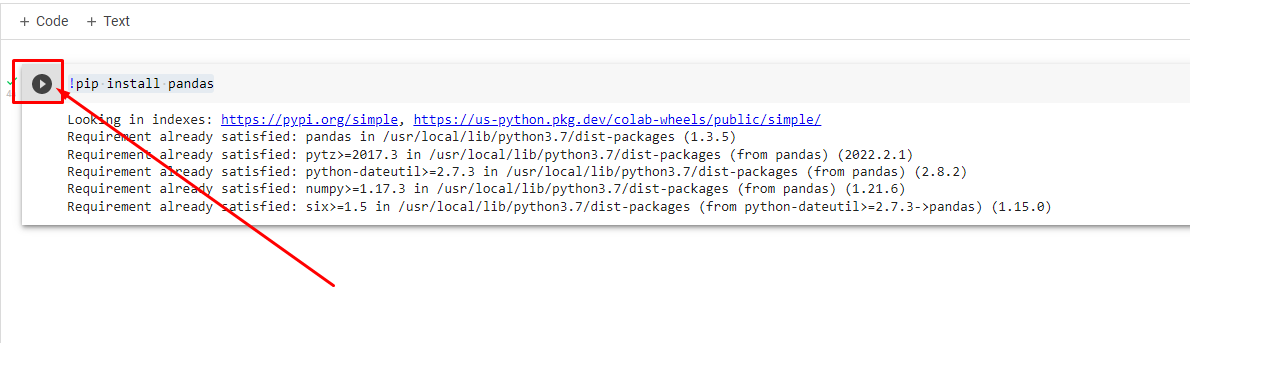 Chạy cài đặt pandas trên colab
Chạy cài đặt pandas trên colab
Gõ xong dòng lệnh thì bấm vào cái biểu tường PLAY bên cạnh nó nó run nhé
Giờ đến thực hiện các việc query và phân tích data nhé. Muốn thêm dòng code thì bấm vào + code
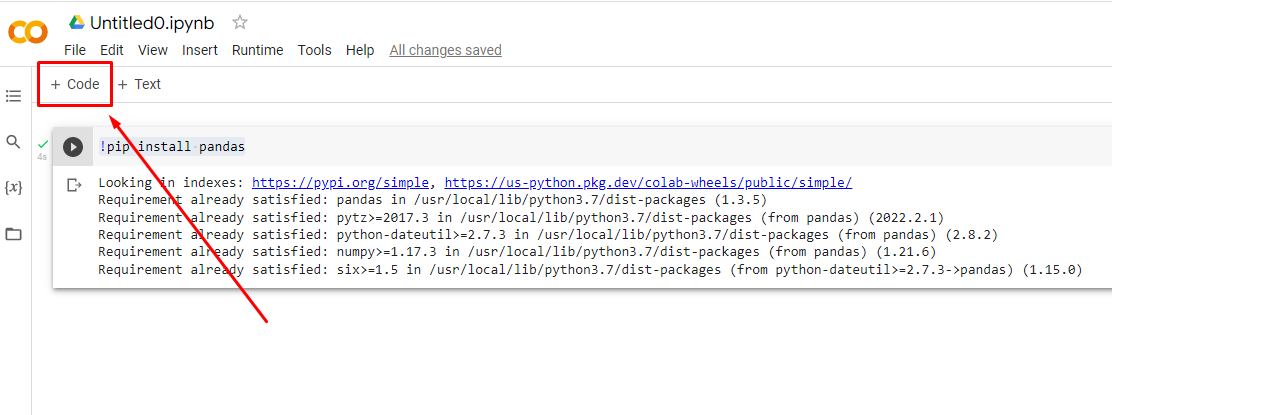
Đầu tiền kiểm tra data của Sinhvien nhé
CODE:
import pandas as pd
ketqua_df = pd.read_csv("./Ketqua.csv")
khoa_df = pd.read_csv("./Khoa.csv")
monhoc_df = pd.read_csv("./Monhoc.csv")
sinhvien_df = pd.read_csv("./sinhvien.csv")
#Xem bảng dữ liệu Sinh viên
print(sinhvien_df)
Giải thích 1 chút chỗ này:
sinhvien_df -- Như kiểu một biến được khai báo
pd.read_csv ('....'): là thư viện pandas được khai báo import pandas as pd - đọc file csv ra
Nếu gặp lỗi thì chắc do chưa tải file CSV lên :D
Tiến hành kiểm tra và tải lại mấy file CSV nhé
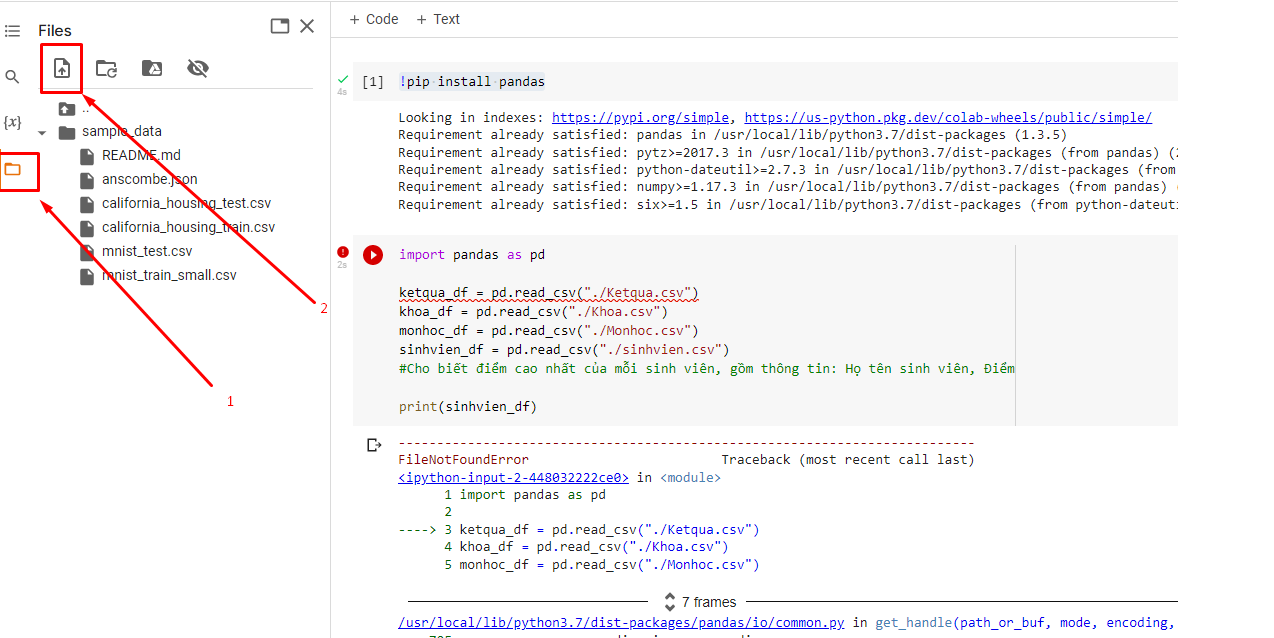 Upload lại mấy file csv
Upload lại mấy file csv
 Đã upload xong mấy file CSV
Đã upload xong mấy file CSV
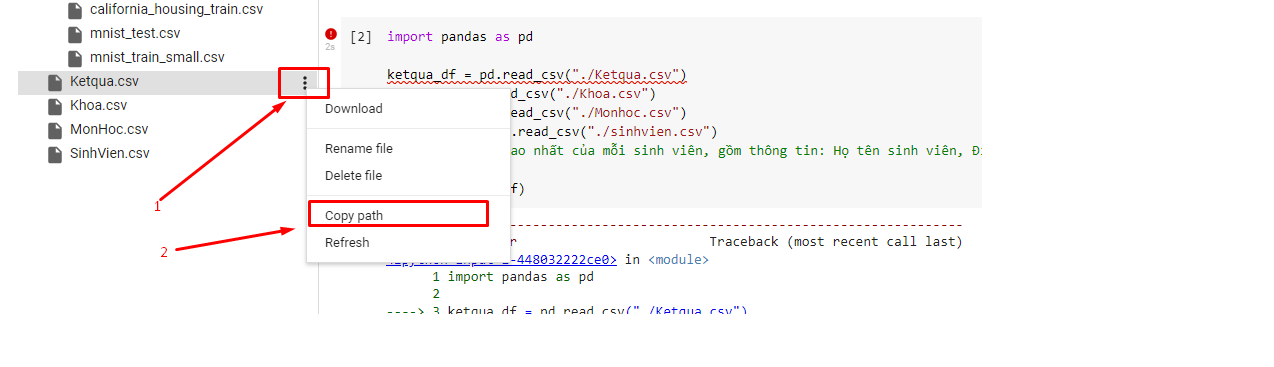 Copy lại đường dẫn file cho chính xác
Copy lại đường dẫn file cho chính xác
Sau khi xong thì chúng ta dán lại link file vào code; của mình sẽ có như thế này
import pandas as pd
#ketqua_df = pd.read_csv("/content/Ketqua.csv")
#khoa_df = pd.read_csv("/content/Khoa.csv")
#monhoc_df = pd.read_csv("/content/MonHoc.csv")
sinhvien_df = pd.read_csv("/content/SinhVien.csv")
##Xem bảng dữ liệu Sinh viên
print(sinhvien_df)
Kết quả xịn xò luôn
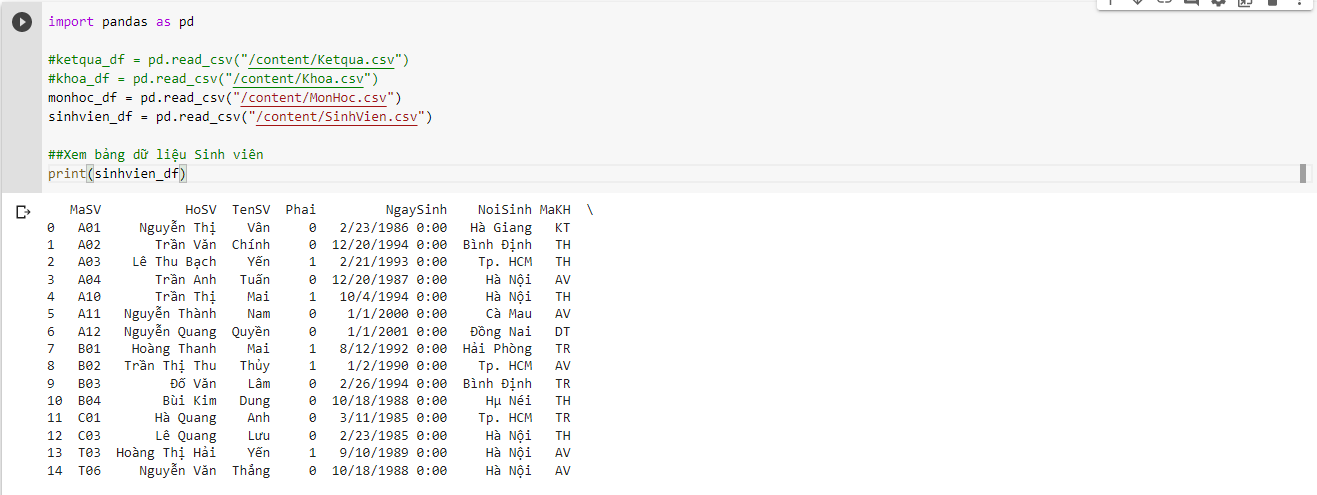 Bảng dữ liệu sinh viên
Bảng dữ liệu sinh viên
Thằng python nó tính từ 0 nhé :D Nên các bạn nhìn dòng cuối là 14 thì tổng sẽ là 15 chú sinh viên đấy
Làm bài Lab của Thầy Chung Trịnh nào.
Lưu ý:
- Thằng colab cái nào phía trước chạy rồi thì phía sau cứ add thêm code mà chạy thôi
- Nếu cái sau chạy bị lỗi thì các bạn chạy lại các phần phía trước. Lười thì bấm CTRL F9
Bài 3 / 4: (trong Lab 4 nhé) # Cho biết tổng số sinh viên ở mỗi khoa, gồm các thông tin: Tên khoa, Tổng số sinh viên
Code:
# Cho biết tổng số sinh viên ở mỗi khoa, gồm các thông tin: Tên khoa, Tổng số sinh viên
df2 = sinhvien_df.groupby('MaKH')['MaSV'].count()
df2 = khoa_df.join(df2,on='MaKH').rename(columns={'MaSV':'Tong'})
print(df2)
Bài 3 / 5: (trong Lab 4 nhé) Cho biết điểm cao nhất của mỗi sinh viên, gồm thông tin: Họ tên sinh viên, Điểm
Code (chạy trên colab nhé)
best_df = ketqua_df.groupby('MaSV')['Diem'].max()
best_df = sinhvien_df.join(best_df, on = 'MaSV')
print(best_df)
Kết quả:
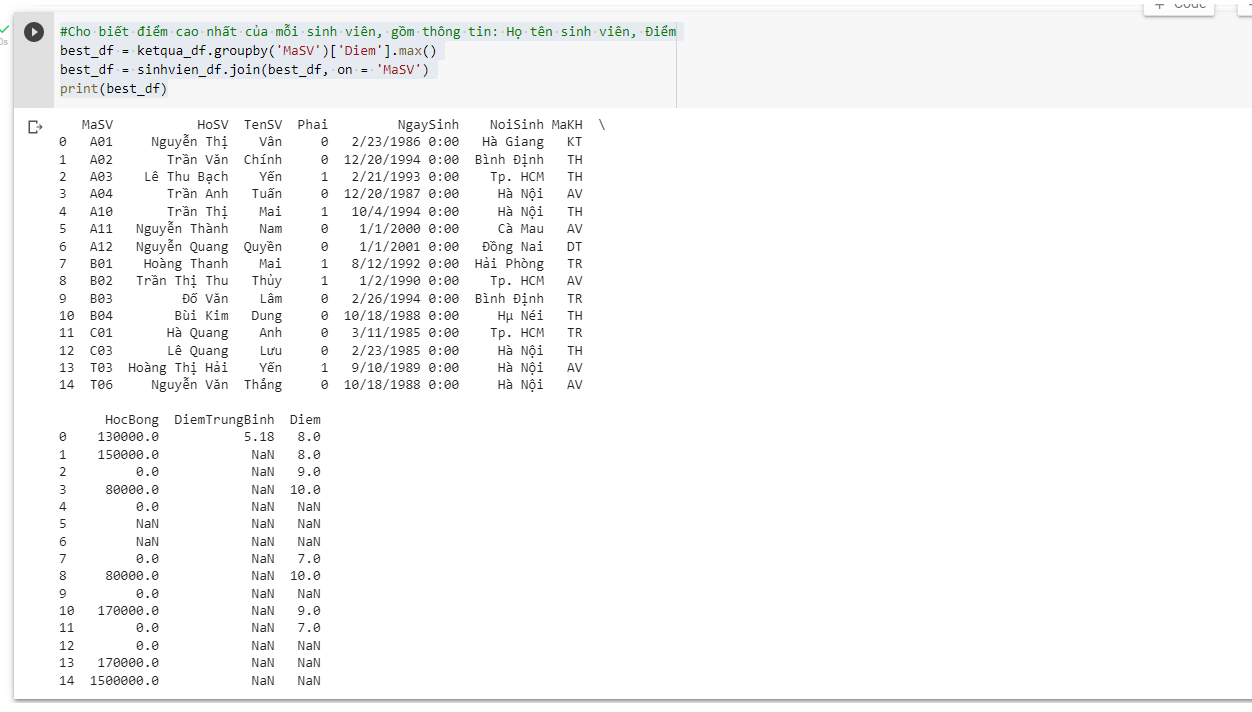 ra kết quả OK - Vì thằng colab nó ko view được nhiều cột nên nó bị nhảy xuống dòng!
ra kết quả OK - Vì thằng colab nó ko view được nhiều cột nên nó bị nhảy xuống dòng!
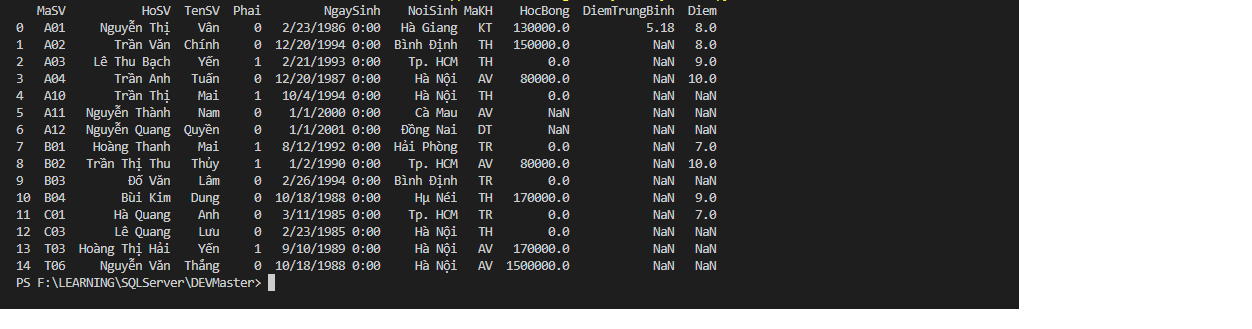 Kết quả trên máy tính.
Kết quả trên máy tính.
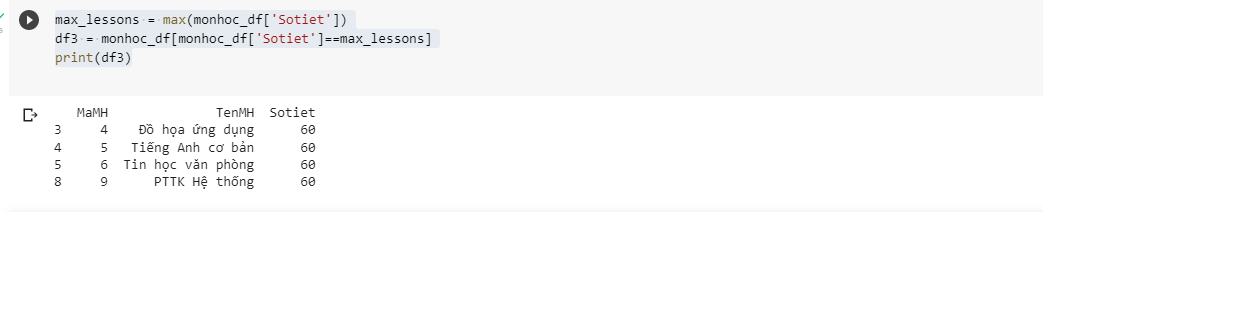
Bài 3 / 6: (trong Lab 4 nhé) #Thông tin của môn học só tiết nhiều nhất: Tên môn học, số tiết
Code
max_lessons = max(monhoc_df['Sotiet'])
df3 = monhoc_df[monhoc_df['Sotiet']==max_lessons]
print(df3)
Kết quả
Bài 3 / 7: (trong Lab 4 nhé) #Cho biết học bổng cao nhất của từng khoa, gồm: Mã khoa, Tên Khoa, Học bổng cao nhất
Code:
#Cho biết học bổng cao nhất của từng khoa, gồm: Mã khoa, Tên Khoa, Học bổng cao nhất
df4= sinhvien_df.groupby('MaKH')['HocBong'].max()
df4 = khoa_df.join(df4,on='MaKH')
print(df4)
Bài 3 / 8: (trong Lab 4 nhé) #Cho biết điểm cao nhất của mỗi môn, gồm: Tên môn, điểm cao nhất
Code:
#Cho biết điểm cao nhất của mỗi môn, gồm: Tên môn, điểm cao nhất
df5 = ketqua_df.groupby('MaMH')['Diem'].max()
df5 = monhoc_df.join(df5,on='MaMH').drop(labels=["MaMH","Sotiet"],axis=1)
print(df5)
Bài 3 / 9: (trong Lab 4 nhé) #Thống kê số sinh viên học của từng môn, thông tin gồm: Mã môn, Tên môn, Số sinh viên đang học
Code
#Thống kê số sinh viên học của từng môn, thông tin gồm: Mã môn, Tên môn, Số sinh viên đang học
df6 = ketqua_df.groupby('MaMH')['MaSV'].count()
df6 = monhoc_df.join(df6,on='MaMH').drop(labels=["Sotiet"],axis=1).rename(columns={'MaSV':'SoSV'})
print(df6)
Bài 3 / 10: (trong Lab 4 nhé) #Thống kê số sinh viên học của từng môn, thông tin gồm: Mã môn, Tên môn, Số sinh viên đang học
...
Trong lúc chờ run project; tớ paste hết code lên cho mọi người tham khảo để run nhé
import pandas as pd
#import pyodbc --> Nếu dùng SQL Server trên chính máy tính cá nân
#chỗ này để đọc hết dữ liệu từ file CSV ra
ketqua_df = pd.read_csv("./Ketqua.csv") #--Nhớ sửa đường dẫn file nhé Chuẩn tên file phân biệt chữ IN và thường
khoa_df = pd.read_csv("./Khoa.csv") #--Nhớ sửa đường dẫn file nhé Chuẩn tên file phân biệt chữ IN và thường
monhoc_df = pd.read_csv("./Monhoc.csv") #--Nhớ sửa đường dẫn file nhé Chuẩn tên file phân biệt chữ IN và thường
sinhvien_df = pd.read_csv("./sinhvien.csv") #--Nhớ sửa đường dẫn file nhé Chuẩn tên file phân biệt chữ IN và thường
#-- Nếu dùng SQL SERVER thì comment mấy cái phía trên lại nhé
#conn = pyodbc.connect('Driver={SQL Server};'
'Server=.\MSSQL2019;'
'Database=DEVMaster_Buoi3;'
'Trusted_Connection=yes;')
#Nhớ sửa lại thông kết nối Database SQL Server chuẩn theo máy tính nhé
#sinhvien_df = pd.read_sql_query('SELECT * FROM sinhvien', conn)
#ketqua_df = pd.read_sql_query('SELECT * FROM Ketqua', conn)
#khoa_df = pd.read_sql_query('SELECT * FROM Khoa', conn)
#monhoc_df = pd.read_sql_query('SELECT * FROM Khoa', conn)
#======================================================
#Cho biết điểm cao nhất của mỗi sinh viên, gồm thông tin: Họ tên sinh viên, Điểm
best_df = ketqua_df.groupby('MaSV')['Diem'].max()
best_df = sinhvien_df.join(best_df, on = 'MaSV')
print(best_df)
# Cho biết tổng số sinh viên ở mỗi khoa, gồm các thông tin: Tên khoa, Tổng số sinh viên
df2 = sinhvien_df.groupby('MaKH')['MaSV'].count()
df2 = khoa_df.join(df2,on='MaKH').rename(columns={'MaSV':'Tong'})
print(df2)
#Thông tin của môn học só tiết nhiều nhất: Tên môn học, số tiết
max_lessons = max(monhoc_df['Sotiet'])
df3 = monhoc_df[monhoc_df['Sotiet']==max_lessons]
print(df3)
#Cho biết học bổng cao nhất của từng khoa, gồm: Mã khoa, Tên Khoa, Học bổng cao nhất
df4= sinhvien_df.groupby('MaKH')['HocBong'].max()
df4 = khoa_df.join(df4,on='MaKH')
print(df4)
#Cho biết điểm cao nhất của mỗi môn, gồm: Tên môn, điểm cao nhất
df5 = ketqua_df.groupby('MaMH')['Diem'].max()
df5 = monhoc_df.join(df5,on='MaMH').drop(labels=["MaMH","Sotiet"],axis=1)
print(df5)
#Thống kê số sinh viên học của từng môn, thông tin gồm: Mã môn, Tên môn, Số sinh viên đang học
df6 = ketqua_df.groupby('MaMH')['MaSV'].count()
df6 = monhoc_df.join(df6,on='MaMH').drop(labels=["Sotiet"],axis=1).rename(columns={'MaSV':'SoSV'})
print(df6)
#Thống kê số sinh viên học của từng môn, thông tin gồm: Mã môn, Tên môn, Số sinh viên đang học
max_score = max(ketqua_df['Diem'])
df7 = ketqua_df[ketqua_df['Diem']==max_score]
df7 = monhoc_df.merge(df7,on='MaMH',how='inner')
print(df7)